
Artificial Intelligence
Get Started with Machine Learning Basics
What Is AI, and Why Should You Care?
The short answer is Artificial Intelligence. Artificial Intelligence refers to any set of computer algorithms designed to automate decision-based tasks. This includes everything from the enemies in a video game to computer-vision applications for detecting breast cancer, financial risk analysis models, large language models and many, many others. When we speak of AI in relation to more advanced applications, however, we are almost always referring to a specific subset of AI called Machine Learning.
Machine Learning
Machine Learning refers to a family of computer algorithms based on applied statistics which enable computer programs to make predictions about the world based on data. It is synonymous with Data Science, as there is little difference between the skillset of a Machine Learning Engineer and a Data Scientist in the majority of cases.
Contrary to a lot of the hype surrounding ML in various developer communities, it is not easy to properly learn. Not only does an ML practitioner need to understand computer programming languages, but also needs a strong background in mathematics, as ML algorithms are replete with statistics and probability theory, linear algebra, multivariable calculus, and data structures and algorithms (DSA).
In this article, we'll walk you through a high-level abstraction of the types of machine learning, so that you can have an easy time digesting conversations using this often overused expression.
Unsupervised Learning
Some forms of AI, very loosely, are simply equations that simulate the ability to make predictions, such as the K-Nearest Neighbours algorithm and Principal Component Analysis techniques. More advanced AI techniques involve building a model that must be "trained"- the computer program has to "learn" how to recognize features in a massive dataset, so that it can later identify them in a totally different dataset.
Supervised Learning
Many types of machine learning algorithms exist, but almost all of them are based on a combination of statistics with differential calculus. We often train the program to make predictions on a dataset, given labels (this is referred to as "Supervised Learning"), and based on how incorrect each set of predictions is across a batch of training data, we compute an aggregate scalar function called the "Loss Function".
We update parameters of our model based on the rate of change of this loss function with respect to the input data, by computing the partial derivatives of the loss with respect to each component of the input data, which is often fed in during training as a vector. This vector of partial derivatives is called the gradient of the loss. There are two techniques from calculus that can be employed in the form of gradient-based-models:
- Express the loss as a Quadratic function, set the derivatives equal to zero, and then solve for the minimum loss resulting from this (Gradient Boosting Trees, e.g. XGBoost)
- Slowly update the parameters of the model along the direction of fastest drop of the loss function, i.e. Gradient Descent (Deep Neural Networks are based entirely on this idea)
Deep Neural Networks
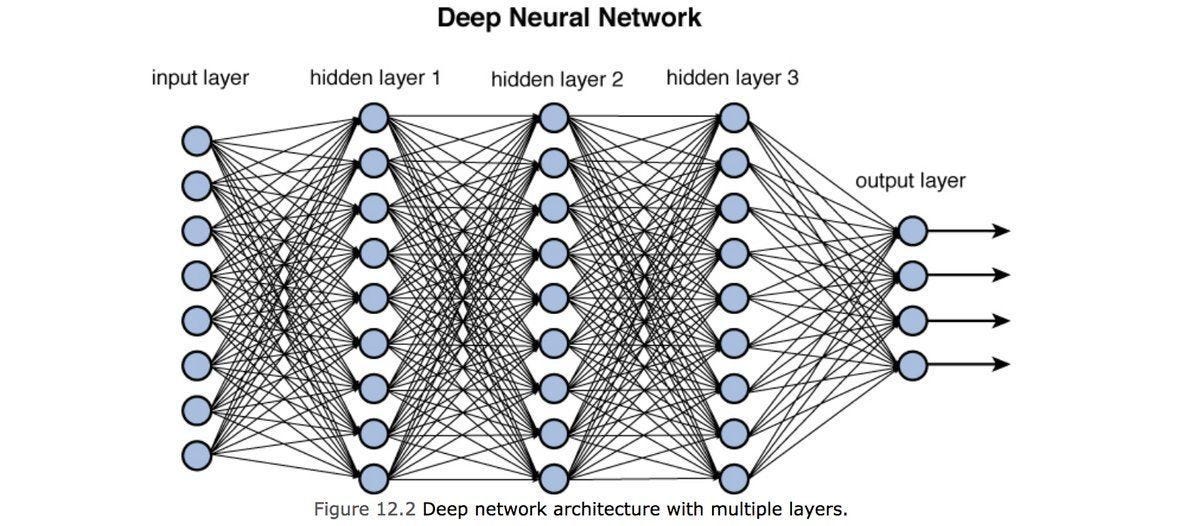
When most people talk about AI, this is what they're usually referring to. A neural network is a structure composed of multiple "hidden layers". These hidden layers are often linear transformations, where the parameters or guts of the model lie within the Weights Matrix and the Bias vector.
Each hidden layer represents a linear system of equations
y = W x + b
Where W is an m x n matrix representing the weights of the layer, y and b are m-dimensional vectors, and y is an n-dimensional input vector.
The components of y are subsequently fed elementwise through an activation function, translating the each component of y into a signal similar to the neuron activations in the human brain. The purpose of this is then to make the outputs differentiable- this way, we can take derivatives of the outputs of each hidden layer, and use them to update the parameters of that layer. This is called backpropagation.
Input vector data (images, word embeddings, audio, etc) is fed into the network in large quantities in order to train it. As the loss function is decreased during each epoch (round) of training, the model becomes more and more accurate as it is learning to make predictions specifically in order to minimize the loss function (error).
This is how your chatbots and AI art tools fundamentally work.
Generative AI
When we speak of Generative AI, we are referring to any artificially intelligent system that is able to produce novel content in a creative way, and is usually able to mimick existing content generation systems (i.e. humans).
There are two dominant architecture styles in Generative AI:
Diffusion Models- Deep learning models based on the Variational Autoencoder (VAE). These are often trained on noisy images, and taught to retrieve the original image from behind the noise (image noise is identical to TV static!)
Transformers- another deep learning model architecture, however one that specifically caters to time-series predictions. These rely on a concept called Self Attention in order to predict the next item in a sequence, and are therefore useful for text generation and summarization, and time-series forecasting.
EquoAI primarily focuses on Transformer-based applications for use by businesses. Our objective here is to help you better understand this technology, and much like a diffusion model, to see the ground truth about the tech behind the noise!